JMX is a Java standard shipped with the JDK since Java 5. Though it enables you to efficiently and dynamically manage your applications, JMX has seen very few productions uses. In this article, I will show you the benefits of using such a technology in a couple of use cases.
Manage your application’s configuration
Even though each application has different needs regarding configuration (one needing a initial thread number attribute, the other an URL), every application needs to be more or less parameterized. In order to do this, countless generations of Java developers (am I overdoing here?) have created two components:
- the first one is a property file where one puts the name value pairs
- the other one is a Java class whose responsibilities are to load the properties in itself and to provide access to the values. This class should be a singleton.
This is good and fine for initialization, but what about runtime changes of those parameters? This is where JMX comes in.
With JMX, you can now expose those parameters with read/write authorizations.
JDK 6 provides you with the JConsole application, which can connect on JMX-enabled applications.
Lets’s take a very simple example, with a configuration having only two properties: there will be one Configuration class and one interface named ConfigurationMBean in order to follow the JMX standard for Standard MBean.
This interface will describe all methods available on the MBean instance:
public interface ConfigurationMBean {
public String getUrl();
public int getNumberOfThread();
public void setUrl(String url);
public void setNumberOfThread(int numberOfThread);
}Now, you’ll only have to register the singleton instance of this class in you MBean server, and you have exposed your application’s configuration to the outside with JMX!
Manage your application’s Springified configuration
In Spring, every bean that is configured in the Spring configuration file can be registered to the JMX server.
That’s it: no need to create an MBean suffixed interface for each class you want to expose.
Spring does it for you, using the more powerful DynamicMBean and ModelMBean classes under the hood.
By default, Spring will expose all your public properties and methods. You can still control more precisely what will be exposed through the use of:
- meta-datas (
@@-like comments in the javadocs, thus decoupling your code from Spring API), - Spring Java 5 annotations,
- classical MBean interfaces referenced in the Spring’s definition file,
- or even using
MethodNameBasedMBeanInfoAssemblerwhich describes the interface in the Spring’s definition file.
More importantly, Spring provides your MBeans with notification provider support.
This means every MBean will implement NotificationBroadcaster and thus be able to send notifications to subscribers, for example when you change a value to a property or when you call a method.
Following is a snippet for the previous Configuration, using Spring:
<bean id="genericCfg" class="ch.frankel.blog.jmx.GenericConfiguration" />
<bean id="exporter" class="org.springframework.jmx.export.MBeanExporter">
<property name="beans">
<map>
<entry key="bean:type=configuration,name=generic" value-ref="genericCfg" />
</map>
</property>
</bean>Spring uses the MBean’s id to register it under the MBean server.
Change a logger’s level
Logging is a critical functionality since the dawn of software. Now, let’s say you are faced with the following problem: your application keeps throwing exceptions but what is traced is not enough for the developers to diagnose. Luckily, one of the developer did put some trace, but on a very primitive level. Unluckily, in production mode, it’s pretty sure you log only important events, mainly exceptions, not the debug informations that could be so useful here.
The first solution is to change the log level in the configuration file and the restart the application. Ouch, that’s a very crude way, one that won’t make many people happy (depending on the criticity and availability of the application).
Another answer is to use the abilities of the logging framework.
For example, Log4J is the legacy logging framework.
It provides a way to configure the framework with a configuration file and to listens to changes made to this file in order to reflect it in the in-memory configuration (the static configureAndWatch() method found in both DOMConfigurator and PropertyConfigurator).This runs fine if you have an external file but what about configuration files shipped with the archive? You can argue that Web archives are often deployed in exploded mode but you cannot rely on it.
JMX will prove to be handy for such a case: if you could have exposed your loggers logging level, you could change them at runtime.
Since JDK 1.4, Java has an API to log messages.
It offers JMX registration for free, so let’s use it.
The only thing to do is create a logger for your class.
In a business method, use the logger to trace at FINE level.
Now using your JMX console, locate the MBean named java.util.logging:type=Logging.
| Type | Name | Description | |
|---|---|---|---|
Attribute |
LoggerNames |
Array of all loggers configured |
|
Operation |
getLoggerLevel |
Get the level of a logger |
The root logger is referenced by an empty string |
Operation |
setLoggerLevel |
Set the level of a logger to a specified value |
|
In order to activate the log, just set the level of the logger used by your class to the value you used in the code. In order to test this, I recomend to create a Spring bean from a Java class using the logger and exporting it to JMX with Spring (see above).
Flush your cache
For the data access layer, Hibernate is the most used framework at the time of this writing. Hibernate enables you to use caching. Hibernate’s first level caching (session cache) is done within Hibernate itself; Hibernate’s second level caching (transsession cache) is delegated to a 3rd party framework. Default framework is Ehcache: it is a very simple, yet efficient solution.
Let’s say some of your application’s table contain repository datas, that is data that won’t be changed by the application. These datas are by definition eligible for second-level caching. Now picture this: your application should be highly available (365/24/7) and the repositories just changed. How can you tell Ehcache to reload the tables in memory without restarting the application?
Luckily, Ehcache provides you with the way to do it.
In fact, the net.sf.ehcache.management.Cache class implements the net.sf.ehcache.management.CacheMBean so you can call all of the interface methods:
one of such method, aptly named removeAll() empties your cache.
Just call it and Hibernate, not finding any data in the cache, will reload them from the database.
You will perhaps object you do not want all of your cache to be reinitialized: now you understand why you should separate your cache instances in the configuration (e.g. one for each table or one for repository datas and one for updatable datas).
Testing JMX
It is legitimate to want to test JMX while developing before bringing in the whole server infrastructure. JDK 6 provides you with the JConsole utility which displays the following informations on any application you can connect to (local and remote):
- memory usage through time,
- threads instances through time,
- number of loaded classes through time,
- summary of VM (including classpath and properties),
- all your exposed MBeans.
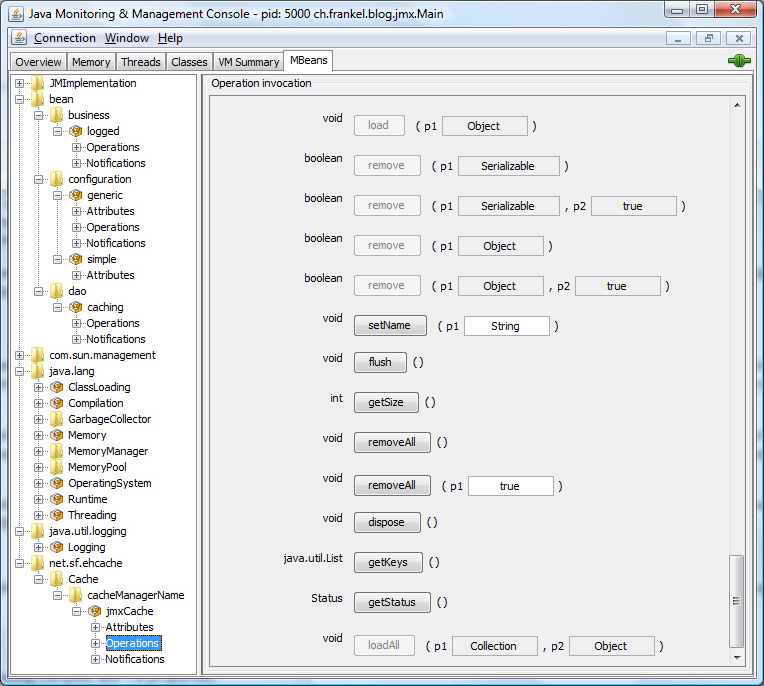
This view lets you view your MBeans attributes and call your MBeans operations, so this is a very valuable tool (for free). Now try it with a legacy application of yours: notice how many MBeans are registered. Guess you didn’t expect that!
In order to use this tool in development mode, do not forget to launch it with the following arguments (notice the -J):
-J-Dcom.sun.management.jmxremote.ssl=false-J-Dcom.sun.management.jmxremote.authenticate=false-J-Djava.class.path="${JDK_HOME}/jdk1.6.0_10/lib/jconsole.jar;${JDK_HOME}/lib/tools.jar;${ADDITIONNAL_CLASSPATH}
The last argument can be omitted in most cases (though this is not the case for managing EhCache).
You can find the sources for all the examples here.