

It’s hard nowadays to ignore Kubernetes. It has become the ubiquitous platform of choice to deploy containerized applications.
Kubernetes is an open-source system for automating deployment, scaling, and management of containerized applications.
In a few years, Kubernetes has entrenched itself deeply in the DevOps landscape under the tutelage of the Cloud Native Computing Foundation. One could speculate about the reasons. IMHO, one very compelling argument is that it allows users to be independent of the API of a single cloud provider. If you’ve been living under the monopoly of Microsoft on the desktop in the 2000’s, you probably know what I mean.
Another reason for Kubernetes to be so widespread is that it’s relatively easy to extend it. In fact, it’s so easy a lot of software providers who offer a Docker image also provide one more operators.
In this 3-parts post, I’ll describe how to start implementing your own controller in a language other than Go, assuming zero knowledge of the subject but Kubernetes itself.
What is a controller?
Configuration management tools can be classified into the following typology:
| Category | Description | Tools |
|---|---|---|
Imperative |
Tell what to do e.g. start 2 additional Hazelcast nodes |
|
Declarative |
Tell what state is desired e.g. have 5 Hazelcast nodes in total |
|
Tools that belong to the declarative category implement the following at regular intervals:
- Query the current state
- Compute the steps between the current state and the desired state
- Apply the steps to achieve the desired state
This algorithm describes a control loop.
In Kubernetes, there already are implementations of such control loops.
For example, consider a ReplicaSet - or a Deployment.
Both allow to set the desired number of replica pods for a dedicated image.
Kubernetes will continue spawning such replicas until the desired number is reached.
If the number is later changed, it will either delete existing replicas if the new count is lower or start new replicas to reach the target count if it’s higher.
Likewise, if a replica pod is deleted while the target count stays the same, Kubernetes will start a new one.
As you might have already guessed by now, a controller is just a control loop implementation of the above steps: check current state, compute diff with existing state and apply diff. In addition to controllers for deployments and replica sets, Kubernetes offers a lot of out-of-the-box controllers:
One could even argue that most resources in Kubernetes are managed by controllers.
The curious case of the operator
Readers interested in controllers might already have stumbled upon the term operator during their search. If your time is very limited, I suggest you skip this section and consider both terms to be close synonyms. If you’re interested in semantics, read on.
As I mentioned in the introduction, Kubernetes is easily extensible.
However, what I didn’t mention is how it is so.
One extension point is to allow to create additional controllers, which is the point of this post.
Another extension point relates to the Kubernetes model itself:
while Pod, Job, etc. are available out-of-the-box, one can provide additional resource types through the usage of Custom Resource Definition.
For example, the following creates a new Hazelcast resource:
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: hazelcasts.hazelcast.com
spec:
group: hazelcast.com
names:
kind: Hazelcast
listKind: HazelcastList
plural: hazelcasts
singular: hazelcast
scope: Namespaced
subresources:
status: {}
versions:
- name: v1alpha1
served: true
storage: trueMaking this new Hazelcast CRD known to Kubernetes is just a matter of applying the previous file:
kubectl apply -f hazelcast-crd.ymlOnce this is done, it’s possible to use the usual verbs on this new resource:
kubectl get hazelcastsIndeed: an operator is a controller that operates upon a CRD instead of a standard resource. As such, an operator IS-A controller, and for all purposes can be considered as one. If one knows how to implement a controller, no additional steps are required to create an operator.
Requirements of a controller
Now, let’s consider the requirements of a Kubernetes controller.
Where to deploy controllers
Here’s a very simplified overview of Kubernetes' architecture.
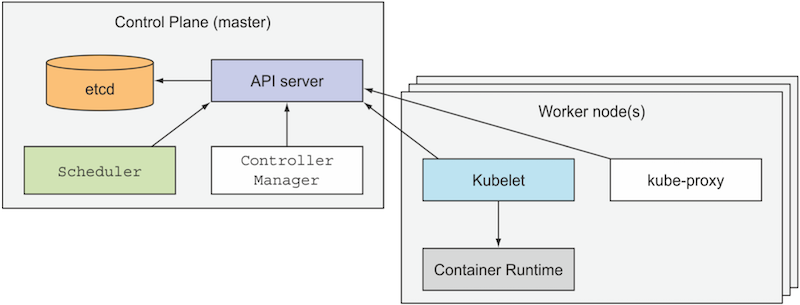
Kubernetes' out-of-the-box controllers are located in the control plane. However, it’s not allowed to deploy one’s own custom controllers there. Apart from that, there are no restrictions: controllers can be deployed either outside or inside the cluster as regular pods.
The latter of course benefits from all advantages of running one’s application inside Kubernetes e.g. self-healing.
Communicating with Kubernetes
In Kubernetes, the API server is the one to communicate with.
One sends it HTTP requests, it does whatever is requested, and sends the response back.
One can check that by using kubectl with the verbose parameter:
kubectl get pods --v=8This prints something like that:
I0209 12:36:31.330067 13717 round_trippers.go:420] GET https://192.168.99.103:8443/api/v1/namespaces/default/pods?limit=500
I0209 12:36:31.330078 13717 round_trippers.go:427] Request Headers:
I0209 12:36:31.330081 13717 round_trippers.go:431] Accept: application/json;as=Table;v=v1beta1;g=meta.k8s.io, application/json
I0209 12:36:31.330085 13717 round_trippers.go:431] User-Agent: kubectl/v1.17.2 (darwin/amd64) kubernetes/59603c6
I0209 12:36:31.339770 13717 round_trippers.go:446] Response Status: 200 OK in 9 milliseconds
I0209 12:36:31.339780 13717 round_trippers.go:449] Response Headers:
I0209 12:36:31.339798 13717 round_trippers.go:452] Content-Length: 2933
I0209 12:36:31.339804 13717 round_trippers.go:452] Date: Sun, 09 Feb 2020 11:36:31 GMT
I0209 12:36:31.339822 13717 round_trippers.go:452] Content-Type: application/json
I0209 12:36:31.340084 13717 request.go:1017] Response Body:
{ "kind":"Table",
"apiVersion":"meta.k8s.io/v1beta1",
"metadata":{
"selfLink":"/api/v1/namespaces/default/pods",
"resourceVersion":"2387836" },
"columnDefinitions":[
{ "name":"Name",
"type":"string",
"format":"name",
"description":"Name must be unique within a namespace. Is required when creating resources, although some resources may allow a client to request the generation of an appropriate name automatically. Name is primarily intended for creation idempotence and configuration definition. Cannot be updated. More info: http://kubernetes.io/docs/user-guide/identifiers#names",
"priority":0 },
{ "name":"Ready",
"type":"string",
"format":"",
"description":"The aggregate readiness state of this pod for accepting traffic.",
"priority":0 },
{ "name":"Status",
"type":"string",
"format":"",
"description":"The aggregate status of the containers in this pod.",
"priority":0 },
{ "name":"Restarts",
"type":"integer",
"format":"",
"description":"The number of times the containers in this pod have been restarted.",
"priority":0 },
{ "name":"Age",
"type":"stri
[truncated 1909 chars]
Communicating with the API server is mainly technology agnostic, requiring only:
- HTTP request/response handling
- JSON parsing (or serialization/deserialization)
That’s right. There’s no additional requirements but HTTP/JSON! Thus, it’s theoretically possible to implement a controller using only the shell. In particular, controllers do not require any specific language - such as Go.
Questioning the place of Go
Before going into the details on how to implement a controller, we should first look at the state of the Kubernetes ecosystem.
The history goes like the ancestor of Kubernetes was originally developed in Java, and was migrated to Go later on. It seems it’s the reason for some of the code to be not idiomatic Go. Despite its garbage-collection feature, Go is touted as a low-level language, well-suited to software that runs close to the bare-metal. Whether that is founded or not is well beyond both the scope of this post and the span of my experience.
However, I believe this is the reason why a lot (if not most) software that belongs to the Kubernetes ecosystem is also written in Go: Istio? Go. Linkerd? Go. containerd? Go. rkt? Go. notary? Go. Jaeger? Go. Prometheus? Go. flannel? Go. And this goes on and on ad nauseam
While it’s perfectly fine to develop in Go if you already are a Go shop, it’s a bit brave if not. This is not congruent to Go itself, but to learn any new language. Actually, "learning a new language" goes much further than just learning the syntax. Just consider the following points:
- How long does it take to write idiomatic code in the new language?
-
I remember when I learned Java reading code written by C developers. While the syntax was Java, the idiom was plain C, including the dereferencing of local variables before the end of the method.
- How long does it take to know the libraries, which one(s) to use in which context, and how to use them?
-
I don’t know about Go, but I know about Java. It’s famous for having a rich ecosystem of libraries. For example, let’s just consider testing. Which libraries should be used: JUnit 4, JUnit 5, TestNG, or something else? Should one add a fluent assertion library? Which one? And this is for testing only!
- How long does it take to choose the right tooling?
-
Granted, it’s easier to move from one JetBrains IDE to another e.g. from IntelliJ IDEA to GoLand, but that’s assuming you’re already using one of them. Nowadays, the IDE space is quite fragmented: Microsoft is pushing VSCode, which requires a lot of plugins. In the Java space, Eclipse still has a sizeable market share. They are all pretty much opinionated, and so are their users. Choosing one over the other might start a holy war inside one’s organization.
- How long does it take to start being productive with this new tooling?
-
None of the IDEs work in the same way. For example, it took me several weeks to stop saving files when I migrated from Eclipse to IntelliJ. And that goes far beyond just the IDE. What about something as trivial as debugging? Does the new language allows it? How? What does it require regarding the launch?
Also, note the above points are only pertaining to development. Investments for a new language can easily amount to twice, or even x times if one accounts for building artifacts, integration and production.
I hope the points above showed beyond any doubt that it requires a non-trivial effort to make the jump to a new language. In a lot of contexts, it might be a much wiser choice to continue using already used languages.
Conclusion
In the first part of this post, we laid the foundations to implement a Kubernetes controller. We detailed what a controller was, and what requirements were necessary: namely, to be able to communicate with HTTP/JSON. In the next post, we are going to go in details and actually develop our own custom controller.