

If "software is eating the world", "data is the new oil". Those who are able to best manage the huge mass of data will emerge out on top. The state-of-the-art way to refine this oil is stream processing.
In this post, I’d like to describe what is stream processing, and why it’s necessary in this day and age.
This is the 1st post in the Stream Processing focus series.Other posts include:
- Introduction to stream processing (this post)
- Stream processing for computing approximations
- Stream processing: sources and sinks
The good old days
The need to move data from one location to another is probably as old as storage itself. This is known as Extract-Transform-Load.
In computing, extract, transform, load (ETL) is the general procedure of copying data from one or more sources into a destination system which represents the data differently from the source(s) or in a different context than the source(s). The ETL process became a popular concept in the 1970s and is often used in data warehousing.
https://en.wikipedia.org/wiki/Extract
When I started my career, the only mode to run ETL processes was batch jobs (or batch). I believe that it’s still the dominant model at the time of this writing, thanks (or due) to the huge legacy of such jobs still making banks run. In general, batches are scheduled to automatically run at regular intervals e.g. every day at midnight, every month, or every year. Sometimes, they are triggered: a daemon process watches over a folder, and when the folder contains files matching a certain pattern, the batch is triggered - and does its work on those files.
Here are some example of batches:
- Datawarehouse
-
SQL databases are normalized, according to several "forms". One of those forms mandates that instead of copying duplicate data into different rows, this data should be put into a dedicated table, and referenced through a primary key-foreign key relationship. The bad side of this approach is that querying over multiple tables requires joins, and that joins slow the execution of the query. With huge loads of data, this can lead to unacceptable waiting times. Thus datawarehouses store data un-normalized.
A monthly (or weekly) batch extracts the normalized data out of the production database, de-normalize it for fast queries, and loads it into the datawarehouse datastore.
- Bank accounts
-
Originally, banks mailed monthly status of one’s accounts by post. With the spread of the World Wide Web, they started to allow users access in digital form. However, for security reasons, the access was not granted to their internal storage, but to a public-facing read-only database.
A daily batch copies all transaction data, as well as related data, from the internal database to the front-end customers database.
Limits of the batch model
As I mentioned above, "data is the new oil". And it’s not mystery that the rate at which data is acquired grows exponentially.
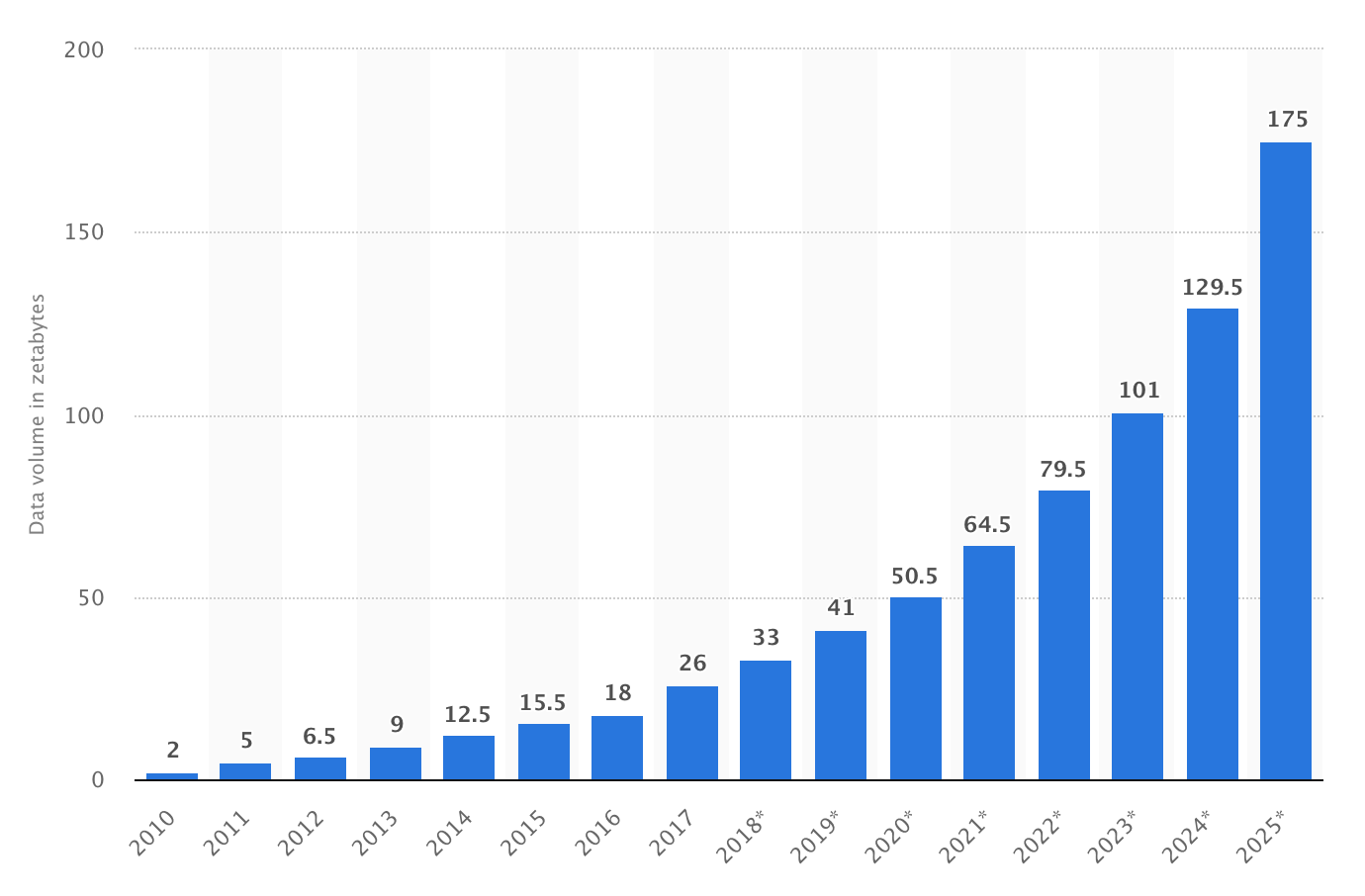
Problems with batching reveals itself when the data’s volume that needs to be processed starts to grow as well.
- The first issue is triggered when the data stored in the database needs to be loaded in memory. If the volume of data doesn’t fit in memory, the batch fails. In general, this is taken care of by the ETL software, which basically loads only the data in chunks, and keeps the start and the end of chunks.
- The second issue happens if the batch needs to be run every period X, and it takes more time than X. The model becomes thus irrelevant. I’ve seen that several times already in my career, and I believe I’m far from the only one. There’s no real way around it. In general, one starts to buy more performant hardware, but it will reach its limits sooner or later.
- Finally, what if the data needs to be available before the batch runs? If one runs a monthly batch, all data will be available for sure at the end of the month. Yet, one needs to wait a whole month to access said data. While this might work for the bank account use-case above, other use-cases might favor getting less complete data as soon as possible. Essentially, batches run at regular periods, and trade off completeness for availability.
The streaming model
Streaming disputes that trade-off, and processes data as soon as it becomes available. It becomes the user’s choice to wait until the period has run its course, or to take decisions at any point, based on incomplete data. The foundation of that approach is that incomplete data now is better than complete data later.
Streaming data is data that is continuously generated by different sources. Such data should be processed incrementally using Stream Processing techniques without having access to all of the data. In addition, it should be considered that concept drift may happen in the data which means that the properties of the stream may change over time.
https://en.wikipedia.org/wiki/Streaming_data
Stream processing is a new way to look at data, and at how it’s handled. In the following posts, I’ll look at some of its different use-cases.