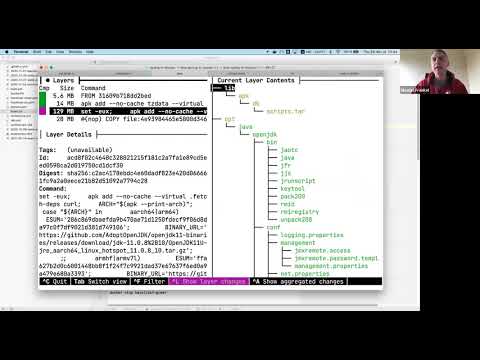
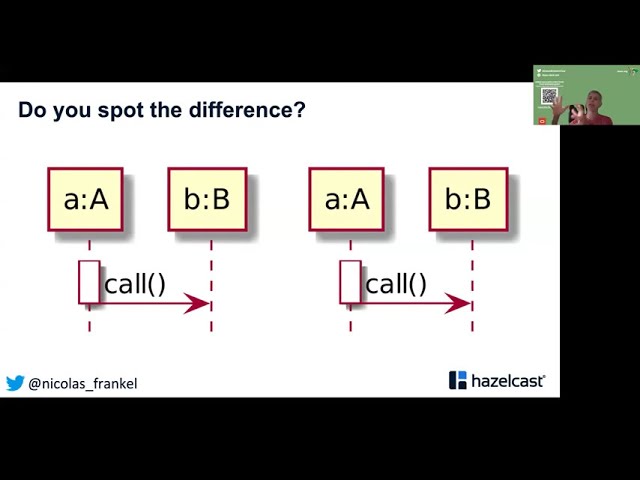
At a point in the past, it was forecast that Java would die, but the JVM platform would be its legacy. And in fact, for a long time, the JVM has been tremendously successful. Wikipedia itself list a bunch of languages that run on it, some of them close to Java e.g. Kotlin, some of them very remote e.g. Clojure. But nowadays, the Cloud is becoming ubiquitous. Containerization is the way to go to alleviate some of the vendor lock-in issues. Kubernetes is a de facto platform. If a container needs to be killed for whatever reason (resource consumption, unhealthy, etc.), a new one needs to replace it as fast as possible. In that context, the JVM seems to be a dead-end: its startup time is huge in comparison to a native process. Likewise, it consumes a lot of memory that just increase the monthly bill. What does that mean for us developers? Has all the time spent in learning the JVM ecosystem been invested with no hope of return over investment? Shall we need to invest even more time in new languages, frameworks, libraries, etc.? That is one possibility for sure. But we can also leverage our existing knowledge, and embrace the Cloud and containers ways with the help of some tools. In this talk, I’ll create a simple URL shortener with a 'standard' stack: Kotlin, JAX-RS and Hazelcast. Then, with the help of Quarkus and GraalVM, I’ll turn this application into a native executable with all Cloud/Container related work has been moved to the build process.